

When a security tool flags dozens of issues but only a small subset are valid, it creates a triage queue that must be processed before reaching the findings that matter.
Detection recall tells you whether a system can find vulnerabilities. It does not tell you the cost of using it. In 2025, that gap became a central bottleneck for teams using AI security tooling in production. This article explains why, and what better measurement infrastructure would look like.
What Is EVMBench and What Does It Measure
EVMBench is a recall benchmark. It provides a curated set of 120 known high-severity vulnerabilities across 40 real audit repositories and measures how many a system detects. This is a genuine contribution: before EVMBench, there was no widely adopted standardized way to compare detection capability across systems on identical codebases at this scale.
However, the structural limitation is precise: EVMBench includes a subset of known vulnerabilities, not the complete set of findings from those audit engagements. To calculate a false positive rate, you need to know everything a system flags, not just whether it found the known items. That data is not in EVMBench.
Curated vulnerability sets are how you build a consistent, reproducible recall test. The limitation is inherent to that design choice, and worth naming clearly because most EVMBench commentary skips it. This limitation has also been discussed in practitioner writeups, for example in recent analysis of AI auditing methodology.
Why Recall Alone Is Not Enough in Security Benchmarks
Early AI security tooling optimized for recall, and recall benchmarks rewarded that. Systems that flagged more findings hit more benchmark items. High recall metrics followed.
In production, those same systems generated output that was difficult to act on. A tool returning dozens of findings per analysis requires significant human effort to triage before any value is extracted. If triage time exceeds the time saved by automated detection, the tool does not fit in the workflow.
By 2025, teams deploying AI security tooling saw the real bottleneck shift. It was no longer whether AI could find vulnerabilities, but whether the output was actionable without generating more work than it saved.
Detection recall is a measure of coverage. Precision is a measure of cost. Teams evaluate on coverage and pay the cost in production. Benchmarks that measure only coverage systematically understate that cost.
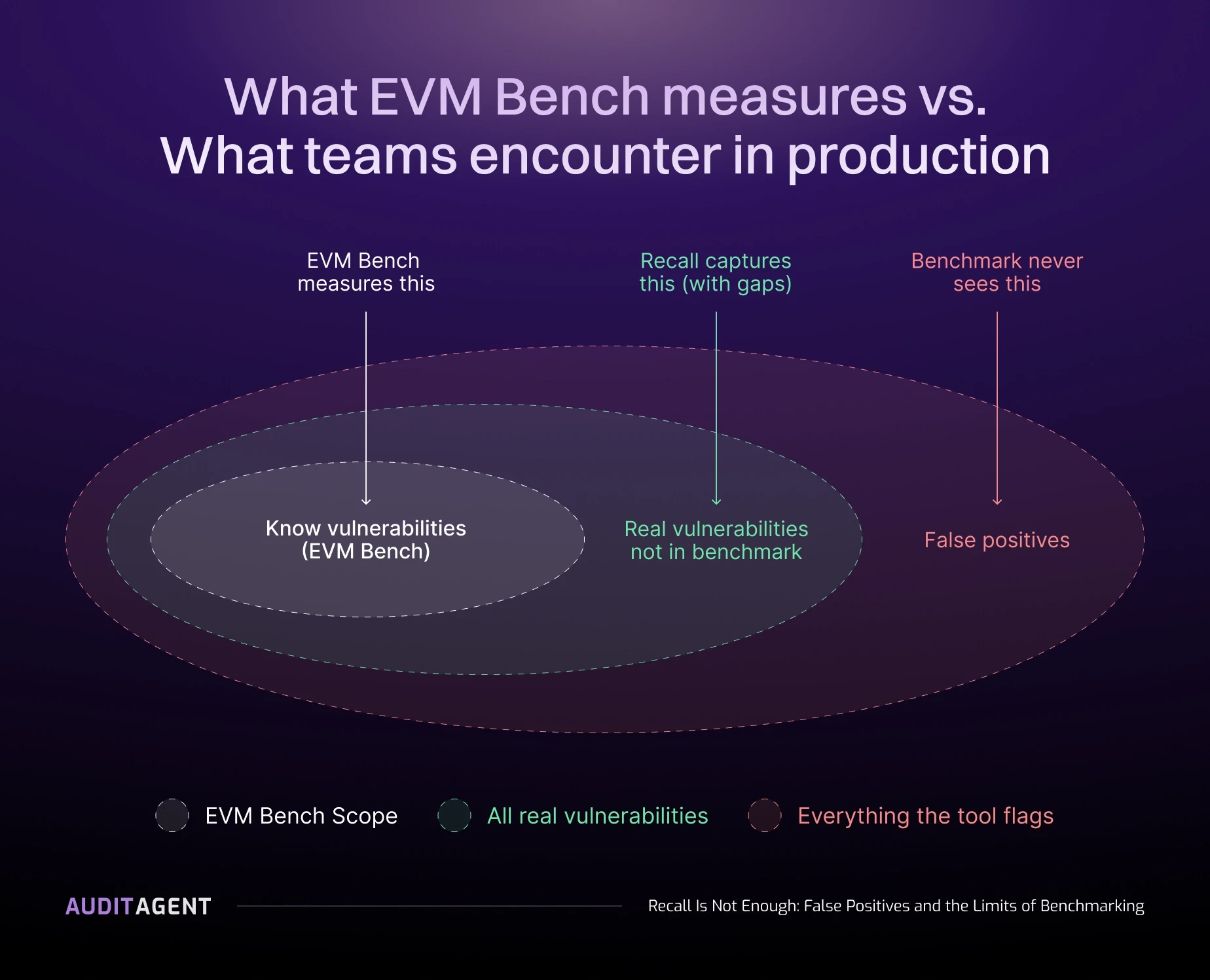
Figure 1: EVMBench scores against the inner ring only. Real vulnerabilities outside the benchmark set and false positives flagged by the tool are both invisible to the benchmark.
How Validation Pipelines Reduce Noise in AI Security Tools
AuditAgent includes a validation phase that filters findings before they are surfaced. The validation layer consists of multiple phases, during which each finding is carefully evaluated in context, and any findings that fail validation are removed.
The published EVMBench recall (67%) reflects post-validation output. Findings filtered out by validation are not included. The result is a smaller, higher-confidence set of findings that auditors can act on directly, rather than a queue of candidates requiring secondary validation. In practice, validation removed 75% of flagged findings (3,230 pre-validation, 798 post-validation) while reducing recall by 7 percentage points.
Why EVMBench Cannot Measure False Positive Rates
Validation pipelines address the problem in practice. They do not close the measurement gap. Without benchmarks that include complete finding sets, there is no standard way to quantify how much noise a system generates or how many true positives are not accounted for and inaccurately reported as false positives.
A team comparing two AI security tools on EVMBench gets recall numbers for both. They do not get false positive rates for either. If Tool A has 65% recall with lower noise and Tool B has 70% recall with higher noise, EVMBench does not surface that difference. The team discovers it in production.
What Is SCABench and How Is It Different from EVMBench
SCABench is a community-driven, open-source benchmark that addresses this directly. Findings are extracted from Code4rena, Cantina, and other competitive audit platforms, with complete finding sets per contest included.
Where EVMBench measures recall, SCABench enables evaluation of both recall and precision on real audit data.
Nethermind contributed to this effort by open-sourcing an evaluation algorithm that classifies findings as true positives, false positives, or partial matches against a ground truth dataset. This evaluation runs separately from the validation layer used during scanning.
What Makes a Good Smart Contract Security Benchmark
The path forward requires complete datasets. Not just: did the system find the known vulnerabilities? But also: what did it flag that was not a vulnerability?
That means:
Benchmark datasets that include all audit findings per engagement, not a curated subset
Evaluation criteria that measure both detection recall and false positive rate
Reproducible methodology that allows third-party verification
Coverage across vulnerability classes that reflect the current attack surface
Even with complete datasets, limitations remain. Some valid findings surfaced by AI systems may not exist in the original audit reports and are therefore counted as false positives, even if they are correct.
AuditAgent Post and Pre-Validation Results
Pre-validation results are included for comparison to illustrate how the validation layer reduces noise before final output.

Figure 2: Validation reduces recall from 74% to 67% while cutting false positives by 75% (3,230 → 798).
AuditAgent’s validation pipeline reduces noise in benchmark detections. That addresses one layer of the problem. Comprehensive audits, formal verification, ZK review, and adversarial AI analysis cover the rest. Nethermind delivers across all of them.
When a security tool flags dozens of issues but only a small subset are valid, it creates a triage queue that must be processed before reaching the findings that matter.
Detection recall tells you whether a system can find vulnerabilities. It does not tell you the cost of using it. In 2025, that gap became a central bottleneck for teams using AI security tooling in production. This article explains why, and what better measurement infrastructure would look like.
What Is EVMBench and What Does It Measure
EVMBench is a recall benchmark. It provides a curated set of 120 known high-severity vulnerabilities across 40 real audit repositories and measures how many a system detects. This is a genuine contribution: before EVMBench, there was no widely adopted standardized way to compare detection capability across systems on identical codebases at this scale.
However, the structural limitation is precise: EVMBench includes a subset of known vulnerabilities, not the complete set of findings from those audit engagements. To calculate a false positive rate, you need to know everything a system flags, not just whether it found the known items. That data is not in EVMBench.
Curated vulnerability sets are how you build a consistent, reproducible recall test. The limitation is inherent to that design choice, and worth naming clearly because most EVMBench commentary skips it. This limitation has also been discussed in practitioner writeups, for example in recent analysis of AI auditing methodology.
Why Recall Alone Is Not Enough in Security Benchmarks
Early AI security tooling optimized for recall, and recall benchmarks rewarded that. Systems that flagged more findings hit more benchmark items. High recall metrics followed.
In production, those same systems generated output that was difficult to act on. A tool returning dozens of findings per analysis requires significant human effort to triage before any value is extracted. If triage time exceeds the time saved by automated detection, the tool does not fit in the workflow.
By 2025, teams deploying AI security tooling saw the real bottleneck shift. It was no longer whether AI could find vulnerabilities, but whether the output was actionable without generating more work than it saved.
Detection recall is a measure of coverage. Precision is a measure of cost. Teams evaluate on coverage and pay the cost in production. Benchmarks that measure only coverage systematically understate that cost.
Figure 1: EVMBench scores against the inner ring only. Real vulnerabilities outside the benchmark set and false positives flagged by the tool are both invisible to the benchmark.
How Validation Pipelines Reduce Noise in AI Security Tools
AuditAgent includes a validation phase that filters findings before they are surfaced. The validation layer consists of multiple phases, during which each finding is carefully evaluated in context, and any findings that fail validation are removed.
The published EVMBench recall (67%) reflects post-validation output. Findings filtered out by validation are not included. The result is a smaller, higher-confidence set of findings that auditors can act on directly, rather than a queue of candidates requiring secondary validation. In practice, validation removed 75% of flagged findings (3,230 pre-validation, 798 post-validation) while reducing recall by 7 percentage points.
Why EVMBench Cannot Measure False Positive Rates
Validation pipelines address the problem in practice. They do not close the measurement gap. Without benchmarks that include complete finding sets, there is no standard way to quantify how much noise a system generates or how many true positives are not accounted for and inaccurately reported as false positives.
A team comparing two AI security tools on EVMBench gets recall numbers for both. They do not get false positive rates for either. If Tool A has 65% recall with lower noise and Tool B has 70% recall with higher noise, EVMBench does not surface that difference. The team discovers it in production.
What Is SCABench and How Is It Different from EVMBench
SCABench is a community-driven, open-source benchmark that addresses this directly. Findings are extracted from Code4rena, Cantina, and other competitive audit platforms, with complete finding sets per contest included.
Where EVMBench measures recall, SCABench enables evaluation of both recall and precision on real audit data.
Nethermind contributed to this effort by open-sourcing an evaluation algorithm that classifies findings as true positives, false positives, or partial matches against a ground truth dataset. This evaluation runs separately from the validation layer used during scanning.
What Makes a Good Smart Contract Security Benchmark
The path forward requires complete datasets. Not just: did the system find the known vulnerabilities? But also: what did it flag that was not a vulnerability?
That means:
Benchmark datasets that include all audit findings per engagement, not a curated subset
Evaluation criteria that measure both detection recall and false positive rate
Reproducible methodology that allows third-party verification
Coverage across vulnerability classes that reflect the current attack surface
Even with complete datasets, limitations remain. Some valid findings surfaced by AI systems may not exist in the original audit reports and are therefore counted as false positives, even if they are correct.
AuditAgent Post and Pre-Validation Results
Pre-validation results are included for comparison to illustrate how the validation layer reduces noise before final output.
Figure 2: Validation reduces recall from 74% to 67% while cutting false positives by 75% (3,230 → 798).
AuditAgent’s validation pipeline reduces noise in benchmark detections. That addresses one layer of the problem. Comprehensive audits, formal verification, ZK review, and adversarial AI analysis cover the rest. Nethermind delivers across all of them.