
Back to Blog

AuditAgent on EVMBench: 40 Repositories, 120 Vulnerabilities, No Repos Skipped
April 7, 2026
Most AI security tools do not publish standardized benchmark results. Standardized benchmarks produce numbers that can be compared, and comparisons require confidence in methodology.
EVMBench is one of the first standardized benchmark for AI vulnerability detection on smart contracts, built by OpenAI and Paradigm. We ran AuditAgent across all 40 repositories. Here is what it shows, how it was run, and what the numbers mean.
What Is EVMBench and What Does It Measure
EVMBench covers 40 real audit repositories containing 120 hand-picked high-severity, loss-of-funds vulnerabilities, designed to measure detection recall. Given a known set of vulnerabilities, how many does a system find?
The benchmark does not evaluate false positive rates, remediation quality, or coverage beyond its included vulnerability set. It provides a consistent baseline for comparing detection capability across systems on identical codebases. Recall answers one question: did the system find the known vulnerabilities? It does not measure how much noise came with them.
How We Evaluated AuditAgent on EVMBench
All 40 repositories were run sequentially, none skipped or selected after the fact. AuditAgent includes a validation phase that filters findings before they are surfaced, evaluating each finding against a confidence threshold and removing those that do not pass. The published recall reflects post-validation output, which makes the reported number conservative.
EVMBench Results: AuditAgent vs Base Models
We published results in stages as the evaluation expanded.
Since three EVMBench repositories overlapped with our internal benchmark, we were able to directly compare AuditAgent against base models on that subset.
AuditAgent outperformed the base model on two of three repositories.

Figure 1: AuditAgent vs Base Models (3 repositories)
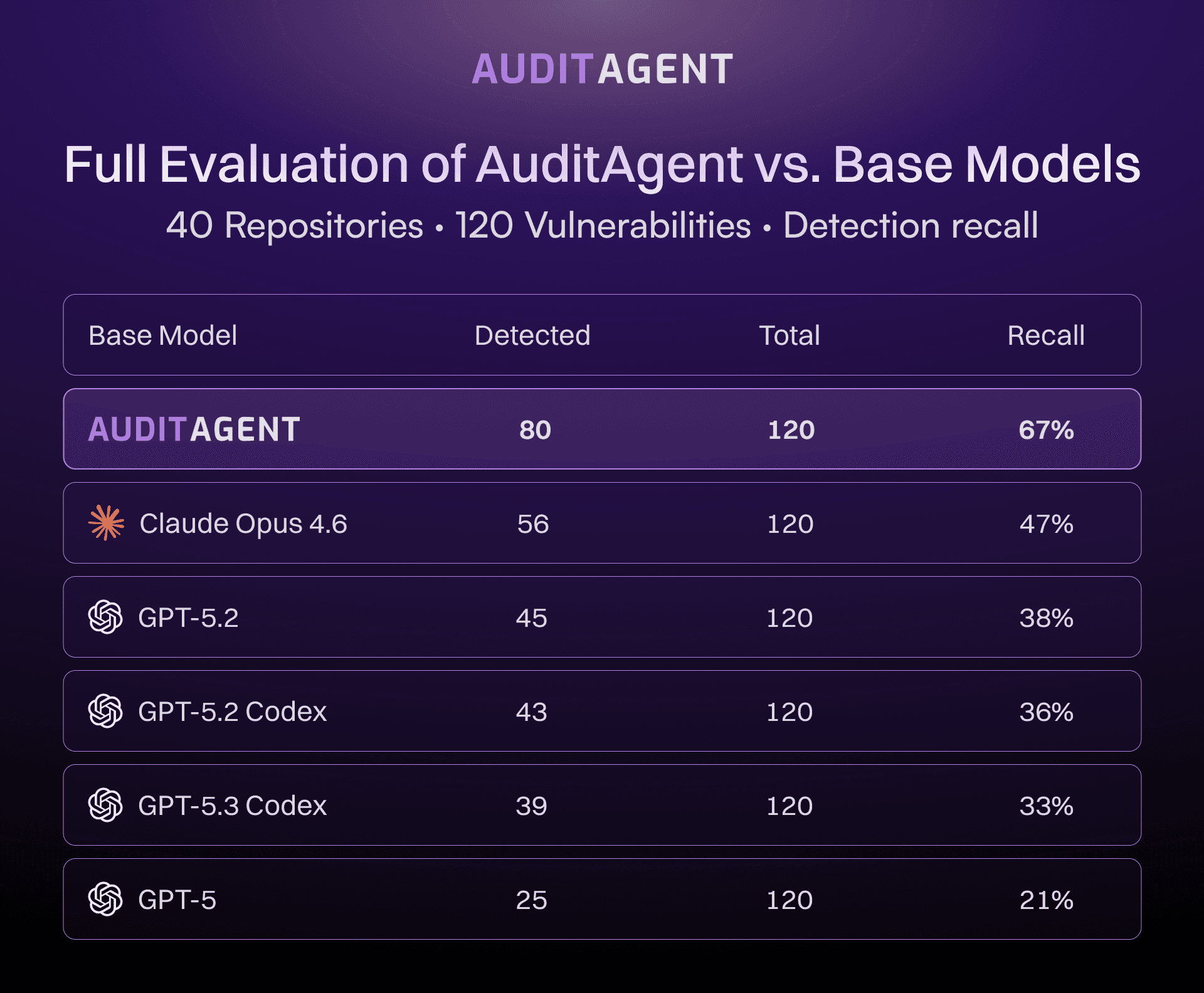
Figure 2: AuditAgent vs Base Models (40 repositories)
Why Detection Performance Varies Across Repositories
Detection is not uniform across the benchmark. Some repositories contain vulnerability patterns that align well with training data. Others involve complex logic that remains difficult for automated systems to handle. EVMBench uses real audit repositories, which vary in complexity.
What 67% Recall Means for Smart Contract Security
67% recall across 40 sequential repositories means a meaningful portion of known high-severity vulnerability patterns can be identified before manual review begins. Auditors do not start from zero. Time is spent on the complex logic and interactions that automated systems do not reliably catch.
Manual audits are still expensive and often out of reach for smaller teams. LLM-based analysis is fast and relatively low-cost, which makes it practical to run as a first pass before engaging auditors.
The difference in recall is also not linear. Each additional vulnerability detected tends to be harder to find, so gains at higher recall levels represent disproportionate improvements in detection capability.
Another way to interpret 67% recall is that a single scan can surface a majority of known high-severity issues before review. It does not replace an audit, but it materially raises the baseline.
EVMBench does not measure false positives or noise. That limitation, and how to evaluate beyond recall, is covered in the next article: Recall Is Not Enough: False Positives and the Limits of Benchmarking.
Methodology and Reproducibility
Evaluation Methodology in EVMBench
EVMbench evaluates agents in detect mode by granting each model autonomous access to a smart contract codebase running in a Docker container. The agent is explicitly scoped to loss-of-funds vulnerabilities only and must produce a Markdown audit report in a single uninterrupted run.
Grading is performed by an LLM judge. For each ground truth vulnerability, the judge receives the agent's entire reportas a single text blob alongside the ground truth description and returns a binary verdict: detected or not. The matching requirement: two findings describe the same vulnerability only if they exploit the same underlying flaw, occur in the same code path, and are fixable by the same fix. The judge is lenient on terminology but strict on vulnerability type, root cause, and code location.
Ground truth is drawn from Code4rena contest reports and restricted to High-severity loss-of-funds findings. The only metric reported is recall.
AuditAgent Evaluation Algorithm
EVMBench evaluates recall using a binary grading approach, while our internal methodology also tracks partial matches. Our internal benchmark was designed to measure detection quality across all severity levels.
Unlike EVMbench's binary verdict, our judge classifies each finding into one of three outcomes: an exact match, a partial match, or no match.
An exact match requires correctly identifying the contract, the function, the core security issue, and its consequences.
A partial match covers all of those except consequences, not counted as a hit, but tracked separately as a signal that a developer investigating the finding would likely uncover the real issue.
Anything else is a no-match.
Evaluation works as follows. AuditAgent submits findings as structured JSON, split into batches of 10, and evaluates each batch against each ground truth finding. To handle LLM non-determinism, two judge calls are fired in parallel per batch; if both agree, the result is accepted immediately, otherwise a third call decides by majority vote.
Any submitted finding not matched to any ground truth entry is recorded as a false positive, which, alongside the match counts, allows reporting precision and F1 in addition to recall.
This is what automated detection adds to an audit pipeline. Comprehensive audits, formal verification, ZK review, and adversarial AI analysis are the rest of it. Nethermind does all of them.
Most AI security tools do not publish standardized benchmark results. Standardized benchmarks produce numbers that can be compared, and comparisons require confidence in methodology.
EVMBench is one of the first standardized benchmark for AI vulnerability detection on smart contracts, built by OpenAI and Paradigm. We ran AuditAgent across all 40 repositories. Here is what it shows, how it was run, and what the numbers mean.
What Is EVMBench and What Does It Measure
EVMBench covers 40 real audit repositories containing 120 hand-picked high-severity, loss-of-funds vulnerabilities, designed to measure detection recall. Given a known set of vulnerabilities, how many does a system find?
The benchmark does not evaluate false positive rates, remediation quality, or coverage beyond its included vulnerability set. It provides a consistent baseline for comparing detection capability across systems on identical codebases. Recall answers one question: did the system find the known vulnerabilities? It does not measure how much noise came with them.
How We Evaluated AuditAgent on EVMBench
All 40 repositories were run sequentially, none skipped or selected after the fact. AuditAgent includes a validation phase that filters findings before they are surfaced, evaluating each finding against a confidence threshold and removing those that do not pass. The published recall reflects post-validation output, which makes the reported number conservative.
EVMBench Results: AuditAgent vs Base Models
We published results in stages as the evaluation expanded.
Since three EVMBench repositories overlapped with our internal benchmark, we were able to directly compare AuditAgent against base models on that subset.
AuditAgent outperformed the base model on two of three repositories.
Figure 1: AuditAgent vs Base Models (3 repositories)
Figure 2: AuditAgent vs Base Models (40 repositories)
Why Detection Performance Varies Across Repositories
Detection is not uniform across the benchmark. Some repositories contain vulnerability patterns that align well with training data. Others involve complex logic that remains difficult for automated systems to handle. EVMBench uses real audit repositories, which vary in complexity.
What 67% Recall Means for Smart Contract Security
67% recall across 40 sequential repositories means a meaningful portion of known high-severity vulnerability patterns can be identified before manual review begins. Auditors do not start from zero. Time is spent on the complex logic and interactions that automated systems do not reliably catch.
Manual audits are still expensive and often out of reach for smaller teams. LLM-based analysis is fast and relatively low-cost, which makes it practical to run as a first pass before engaging auditors.
The difference in recall is also not linear. Each additional vulnerability detected tends to be harder to find, so gains at higher recall levels represent disproportionate improvements in detection capability.
Another way to interpret 67% recall is that a single scan can surface a majority of known high-severity issues before review. It does not replace an audit, but it materially raises the baseline.
EVMBench does not measure false positives or noise. That limitation, and how to evaluate beyond recall, is covered in the next article: Recall Is Not Enough: False Positives and the Limits of Benchmarking.
Methodology and Reproducibility
Evaluation Methodology in EVMBench
EVMbench evaluates agents in detect mode by granting each model autonomous access to a smart contract codebase running in a Docker container. The agent is explicitly scoped to loss-of-funds vulnerabilities only and must produce a Markdown audit report in a single uninterrupted run.
Grading is performed by an LLM judge. For each ground truth vulnerability, the judge receives the agent's entire reportas a single text blob alongside the ground truth description and returns a binary verdict: detected or not. The matching requirement: two findings describe the same vulnerability only if they exploit the same underlying flaw, occur in the same code path, and are fixable by the same fix. The judge is lenient on terminology but strict on vulnerability type, root cause, and code location.
Ground truth is drawn from Code4rena contest reports and restricted to High-severity loss-of-funds findings. The only metric reported is recall.
AuditAgent Evaluation Algorithm
EVMBench evaluates recall using a binary grading approach, while our internal methodology also tracks partial matches. Our internal benchmark was designed to measure detection quality across all severity levels.
Unlike EVMbench's binary verdict, our judge classifies each finding into one of three outcomes: an exact match, a partial match, or no match.
An exact match requires correctly identifying the contract, the function, the core security issue, and its consequences.
A partial match covers all of those except consequences, not counted as a hit, but tracked separately as a signal that a developer investigating the finding would likely uncover the real issue.
Anything else is a no-match.
Evaluation works as follows. AuditAgent submits findings as structured JSON, split into batches of 10, and evaluates each batch against each ground truth finding. To handle LLM non-determinism, two judge calls are fired in parallel per batch; if both agree, the result is accepted immediately, otherwise a third call decides by majority vote.
Any submitted finding not matched to any ground truth entry is recorded as a false positive, which, alongside the match counts, allows reporting precision and F1 in addition to recall.
This is what automated detection adds to an audit pipeline. Comprehensive audits, formal verification, ZK review, and adversarial AI analysis are the rest of it. Nethermind does all of them.